


In AB testing, everyone talks about this best practice of ensuring tests reach 95% statistical significance before declaring a winner. But here is something most casual AB testers often don’t know: just because a test reaches 95% statistical significance, it doesn’t mean the results are valid and it doesn’t mean you should immediately stop it.
In this article we’ll illustrate why and explain what are proper safeguards to stopping a test. We’ll do that by starting with an illustrative example.
Here is a test we ran for an ecommerce client:
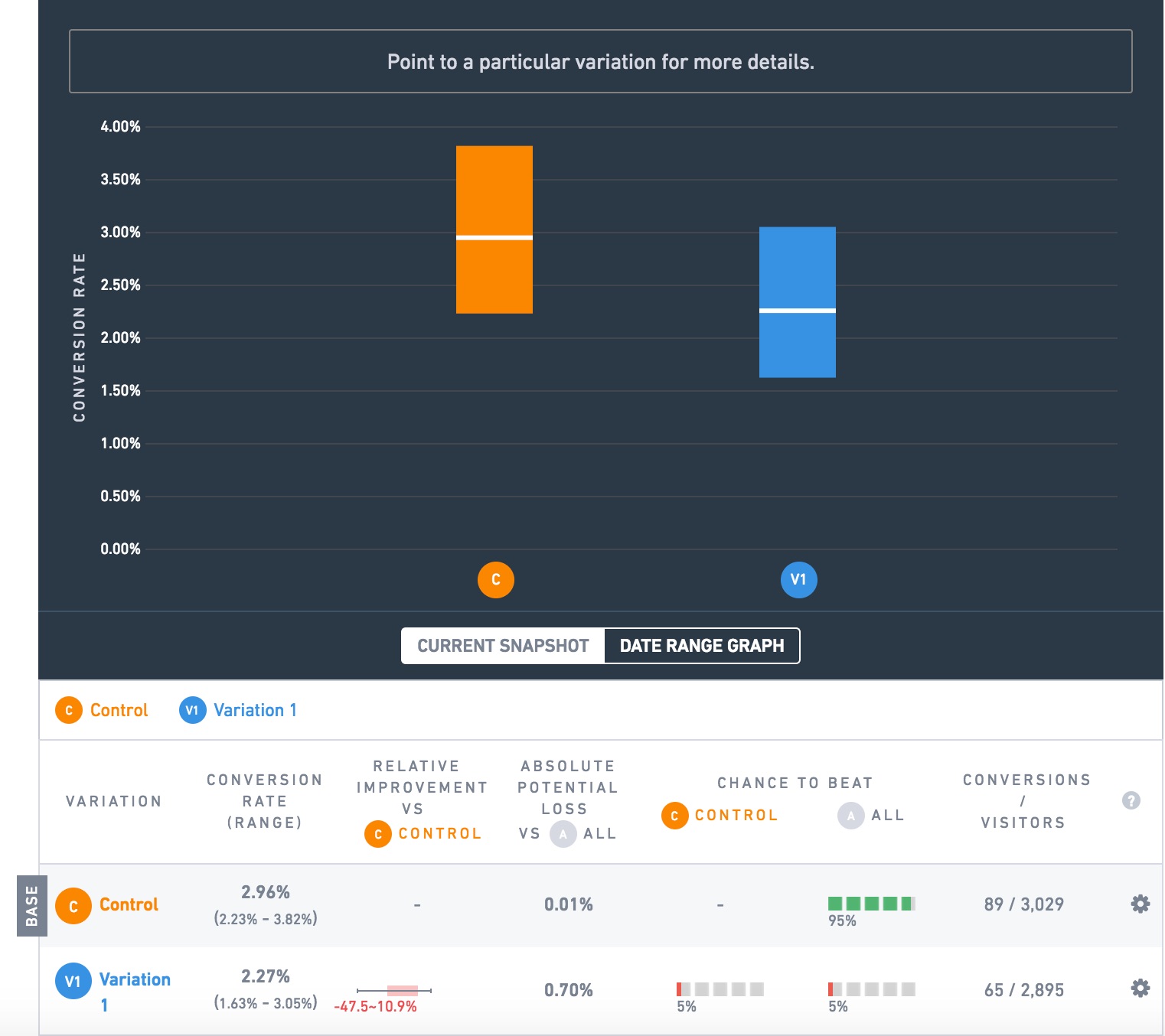
The goal we are measuring here is successful checkouts (visitors reaching the receipt page). The orange variation is beating the blue by 30.4% (2.96% vs. 2.27%), and the test shows 95% “chance to beat” or “statistical significance”!
That’s a big deal. This client has an 8 figure ecommerce business. Let’s say it’s $30 million a year in revenue and that this test is on a universal element like the navbar that is on every page of the site, so the lift applies to all traffic. A 30% lift in orders would be worth $9,000,000 in extra revenue a year!
This lure of extra revenue is enticing. Very much so. So much so that it can lead otherwise well-meaning people to make a grave mistake: stopping a test too early.
In this case, you might be tempted to think: well the test has run for reached 95% significance, which everyone says is the cutoff. It had 3000 visitors to each variation. This is convincing. Let’s stop the test and run the orange variation at 100%!
But here’s a secret: both variations were the same.
This was, in CRO parlance, and A/A test. We ran it not to “test significance” which Craig Sullivan, in that preceding link argues is a waste of time (and I agree), not to give us an opportunity to look smart by writing this article, but just to check if revenue goals were measuring properly (they were, thank you for asking).
So how in the world are you supposed to know that this test is not worth stopping? Or as CRO people say, how do you know when you’re supposed to “call” the test?
You actually need two safeguards to make sure you don’t get duped by random fluctuations of data, i.e. statistical noise.
Safeguard 1: Statistical Significance
Safeguard 2: Sample Size
In this case we saw it satisfied the first safeguard, statistical significance. But that’s why the 2nd safeguard, sample size, exists. This test only had 89 and 65 conversions per variation. That’s generally not enough. There is no hard and fast rule for how many visitors or conversions a test needs to be a big enough sample size. But you can use this famous Evan Miller sample size calculator to give you one estimate. As a general rule though, shoot for at least 100 conversions per variation. Many CRO blogs I’ve read say it should be more like 200 or 400 conversions per variation.
Why? Why is sample size important?
Because it helps ensure that situations like the above where random chance just puts a bunch more conversions in one variation (and the testing software says the difference in conversion rate is 95% statistically significant) don’t happen. It can’t stop it from happening. All of AB testing involves testing a sample (the people who hit your test while it’s on) and extrapolating to the future, so you can never be sure your results will hold, but a bigger sample size helps minimize this.
Safeguard 3: Time
Finally, we also rarely stop tests before they’ve run for 2 calendar weeks. Ecommerce purchases happen on a weekly cycle, with purchase behavior on Saturday and Sunday obviously being different than weekdays. So making sure that any differences in results hold after 2 of those cycles complete also ensures that we’re not over-reacting to some short term effect skewing results.
As an extreme example to illustrate this point, say you run a test that adds emphasis to a message saying a sale ends on Friday. You start this test on Wednesday. It’s quite likely that hwen you check the results on Thursday or Friday the variation which emphasizes that message is showing a higher conversion rate than the control. But how high? Its effect is likely to be much weaker on Saturday – Tuesday. Stopping this hypothetical test on Friday and declaring a 50% lift is not responsible. Wait at least 2 weeks and see what the effect is over a longer time period.
Or Decide On A Set Sample Size Ahead of Time (Safeguard #4)
Alternative to all this is a well regarded best practice in AB testing: just decide ahead of time how long you will run a test, stop the test when it hist that number of visitors or time period, and only declare winners for tests that meet your statistical significance threshold. This is strictly speaking, the proper way to do AB testing.
It’s explained well in this accompanying article to the Evan Miller sample size calculator.
Warning: that is a long and mathematical explanation. But in short because of the example I opened up with in this post, the idea is that tests will come in and out of statistical significance if you keep them running, so if you automatically stop tests the moment they hit your stat sig threshold, you’re likely counting winners when there are none.
The problem with this is many clients and businesses refuse to do it. They want to see results as they go. They want to make a call before set sample sizes, and the real world is rarely this clean and neat. A classic example is a test that you run for a while, say 4 weeks, it has tens or hundreds of thousands of visitors per variation, the variation is beating the original for almost the entire test and the statistical significance hovers at 92% for multiple weeks. How many ecommerce brands and management teams are willing to declare that no difference and move on? Very few in my experience. I think it’s okay to make a business decision there and implement the variation. You got the data (the variation was likely better than the original), and you are taking a calculated risk — specifically there is an 8% chance that there is no difference rather than a 5% chance.
As a way of accommodating this “business reality” of AB testing ecommerce sites, at Growth Rock, we also are careful to watch of statistical significance holds for multiple days or ideally weeks. If it does, then we know that we could have stopped the test a few days ago and nothing would have changed — we aren’t just insta-stopping it the moment it hit 95% statistical significance. Yes, this is not, strictly speaking, the “proper” way to declare validity, but we are making a calculated business decision and aware of the risks.
Finally, if you still need more convincing on this point, consider the common scenario of a test showing no difference and the brand implementing the variation anyways. Is that irresponsible of the brand? Absolutely not. That would be like saying “never make a change to your site that’s not AB tested”. I’ve heard that stated in forums and discussion boards. It’s a nonsensical idea. Of course business decisions, branding decisions, and marketing decisions need to be made all the time that you can’t AB test. Very few TV and radio ads over the years have been AB tested. That doesn’t mean they are bad or hurt the company. It simply means the business is taking a risk.
AB testing is simply a way of gathering some data that helps give you confidence that a change is more likely to help than hurt. There are times in the real world that that data will be imperfect. It won’t mean the laboratory criteria for a “winner”. That’s okay. the key is being aware and knowing that that risk is there — knowing what the data told you and just as importantly, what it didn’t tell you. If you are aware, you can still act on that data as you wish.
Bonus Points: Use Multiple Goals
Finally, in addition to the two safeguards above, you should also make sure you are tracking multiple goals through your purchase or signup funnel. You should be paying attention to supporting goals. Do the supporting goals show a consistent result? (They don’t have to, and they may not, but it’s good to know). In the A/A test example above, most actually did, but some did not, for example, here is the goal that tracks clicks on the size dropdown on the PDP, the results show largely no difference at all (note 45%, 55%, even chance of beating each other):

Tracking multiple goals will help give you a more holistic picture of what’s happening. I’m not saying all goals have to show the same result for a test result to be valid. But if just one or two goals are showing a big difference but the others aren’t, you should ask why that could be.
1 Comment
Graeme Sutherland
April 20, 2017Growth Rock is the real deal Devesh! – but you know that… 🙂 Great post. Again.